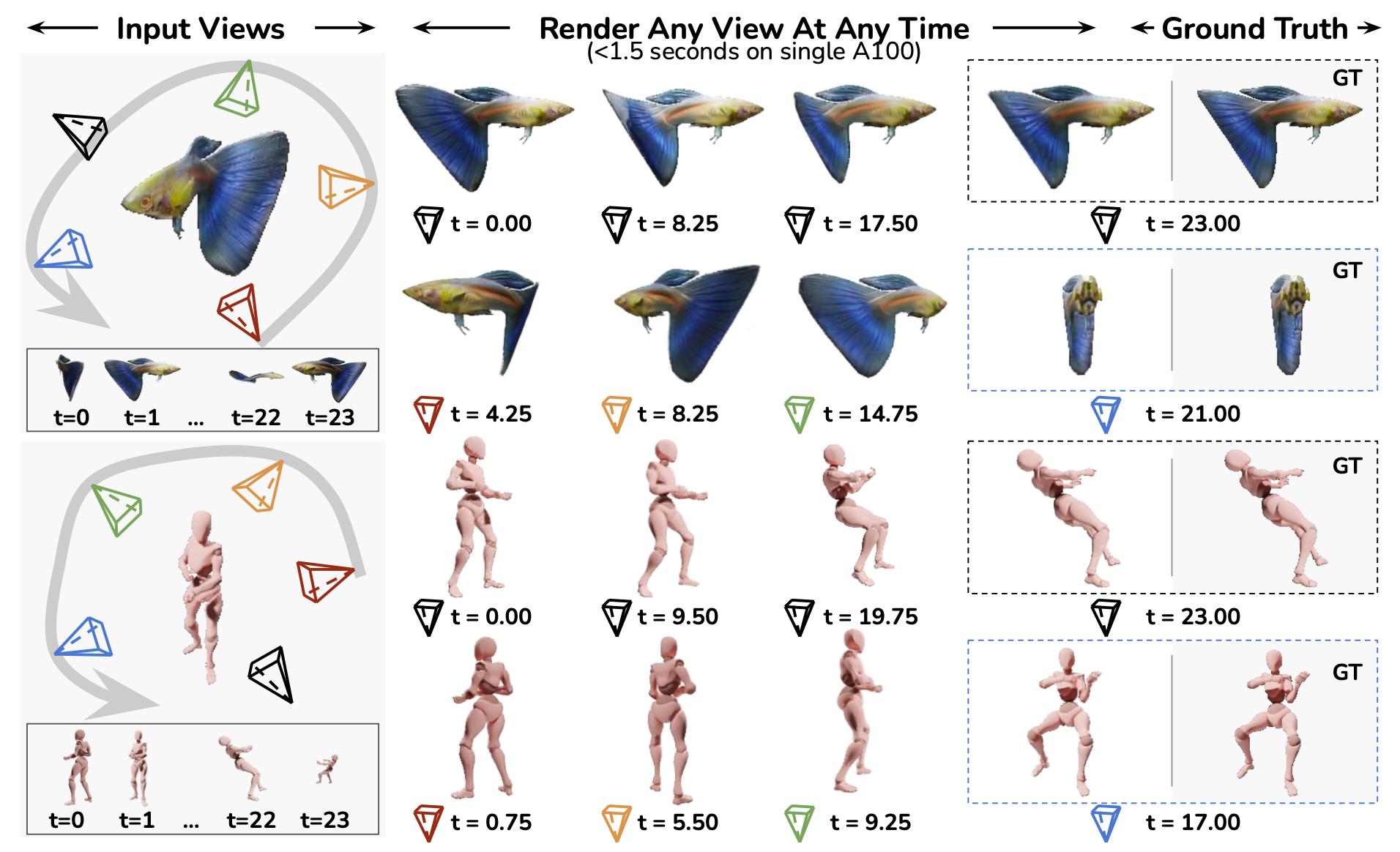
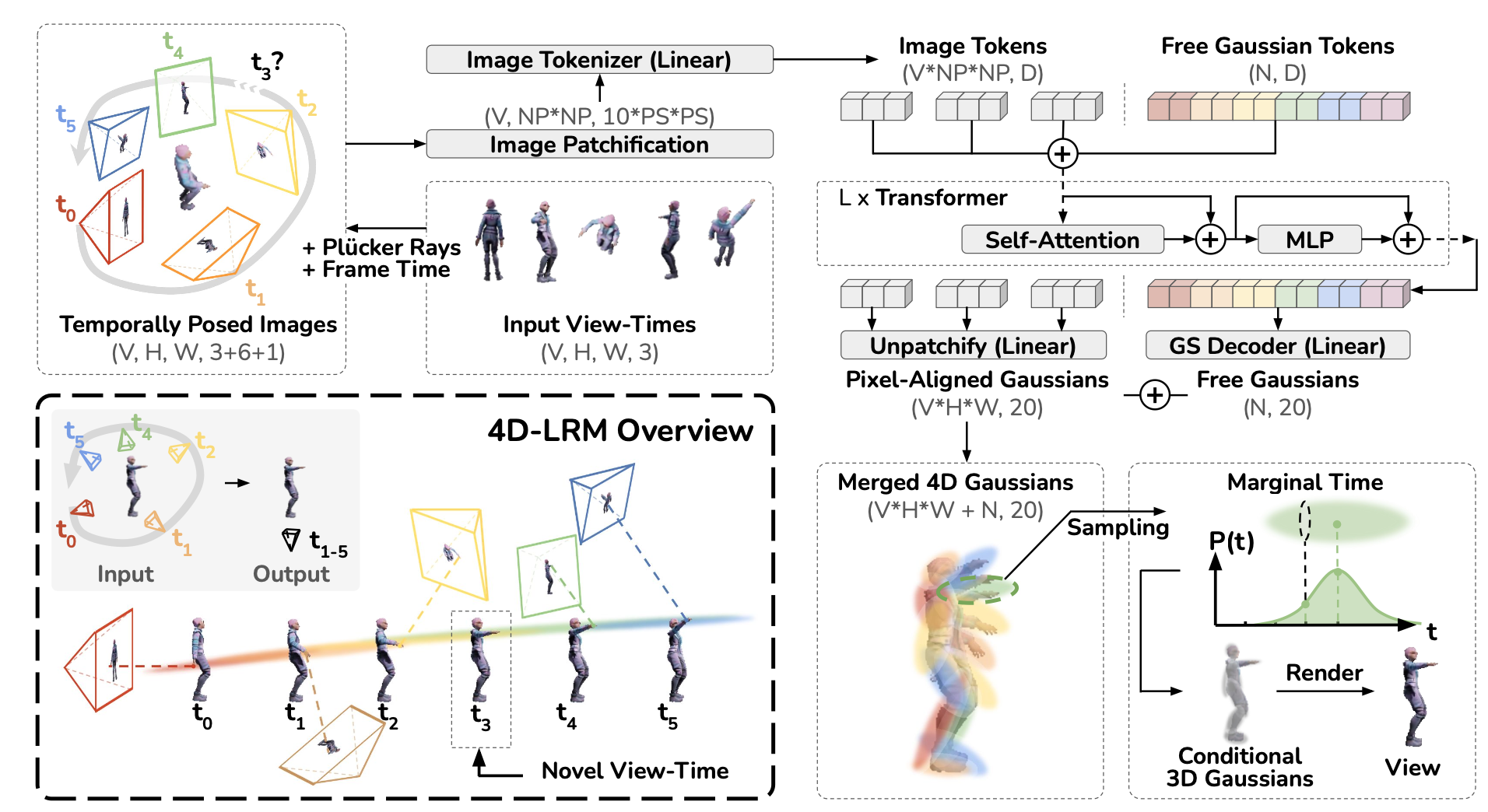
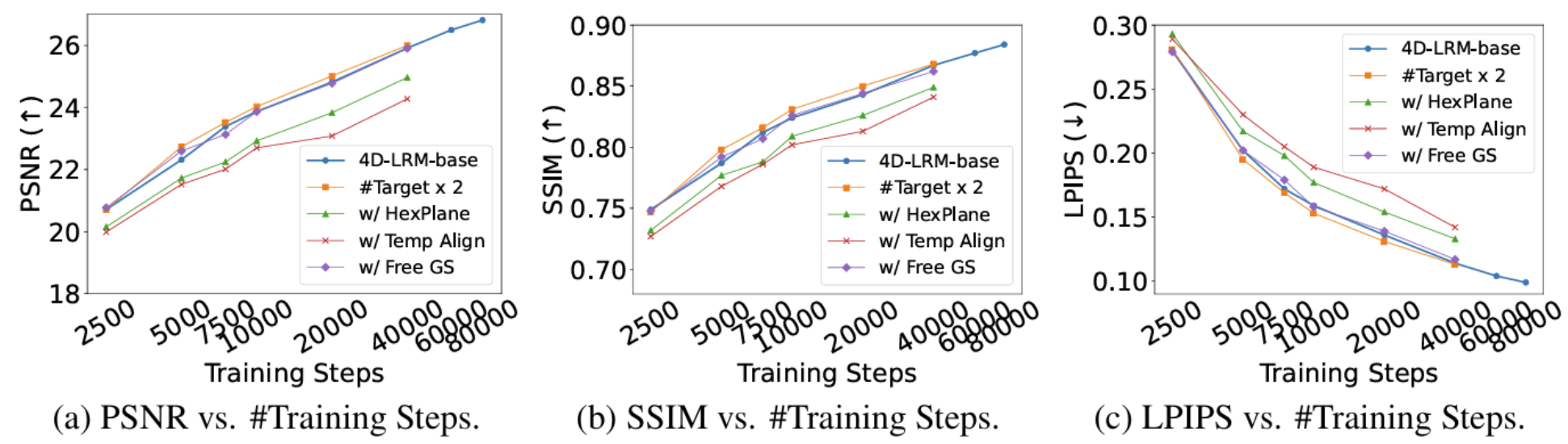
Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimizationbased, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View
Front View
Back View
Left View
Right View
Turntable View

@article{ma20254dlrm,
title={4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time},
author={Ziqiao Ma and Xuweiyi Chen and Shoubin Yu and Sai Bi and Kai Zhang and Ziwen Chen and Sihan Xu and Jianing Yang and Zexiang Xu and Kalyan Sunkavalli and Mohit Bansal and Joyce Chai and Hao Tan},
year={2025},
journal={arXiv:2506.18890},
}